A presentation delivered by me at a local test meet up group – VanQ – on the 23rd February 2017
PDF version of the slides: Where_Is_The_Risk_VanQ
Video of the presentation: YouTube – Where is the Risk
A presentation delivered by me at a local test meet up group – VanQ – on the 23rd February 2017
PDF version of the slides: Where_Is_The_Risk_VanQ
Video of the presentation: YouTube – Where is the Risk
Why don’t we have time to do it right, but somehow we do have time to do it twice?
My paraphrase of a quote by John Wooden
How come we often think it is better to rush into something we don’t understand and hack at it than to take the time to understand what it is we are really trying to achieve and then think about how we will achieve that before we start coding?
Do we not learn from our mistakes?
Do we not see, measure or understand the cost of halting a developer, who is by now working on another story, to get them to switch context and think back to the rushed coding they did on the previous story. To get them to diagnose the root cause of the bug we just discovered? Or see, measure or understand the time it takes to diagnose, resolve then rebuild and re-test this change through the entire pipeline? With a very real risk that when handed back to the tester that she will find another issue as the fix was rushed and we did not have enough coverage in our pipeline of automated checks to discover the regression that was introduced.
I have seen this pattern throughout my life and have been guilty of it myself. So what do I do about it?
Well I try to discipline myself, but what I do for my teams is to use BDD to ensure we have shared and common understanding of what story we are about to do, changes we are about to make, additions we are introducing. To ensure we all understand who needs these changes and why they are important to them. (Who the customer is and why they care). Then we, (the three amigos – slide 9), will be able to agree some high level examples of what ‘done’ looks like for this piece of work. These examples will be in the the form of tests that will adequately specify and thus prove we have delivered what was required. We call these the acceptance tests. They are defined before any coding is started. Hence the ‘driven development’ part of BDD. Where possible these tests are automated and are required to be passed, (via automation or manual checking), before the story is pulled by QA, (we use Kanban), to do a final exploratory test.
We are not perfect at this, but it really does mean that we can get a story accepted more often than not on its first pass through the pipeline. If it doesn’t we all understand the work well enough to learn from the mistake(s) and improve.
Following on from the UNUSUAL PAGE post, I have also created a heuristic for REST APIs, along with a simple mnemonic, which I think is quite memorable for a certain group of sci-fi fans 😃
My organisation is currently implementing an API first strategy, whereby we design and implement the API for any piece of functionality before developing any UI or consumer code for that interface. This provides us with the ability to separate concerns easily, improves testability and is in line with the current trend for micro services.
As with the UNUSUAL PAGE mnemonic I realised that the original heuristic was not that memorable and thus my team were not able to easily call it to mind when in a meeting room, designing the next REST API with their team.
So, with a bit of rephrasing I came up with VADER, (Verbs, Authorization, Data, Errors, Responsiveness).
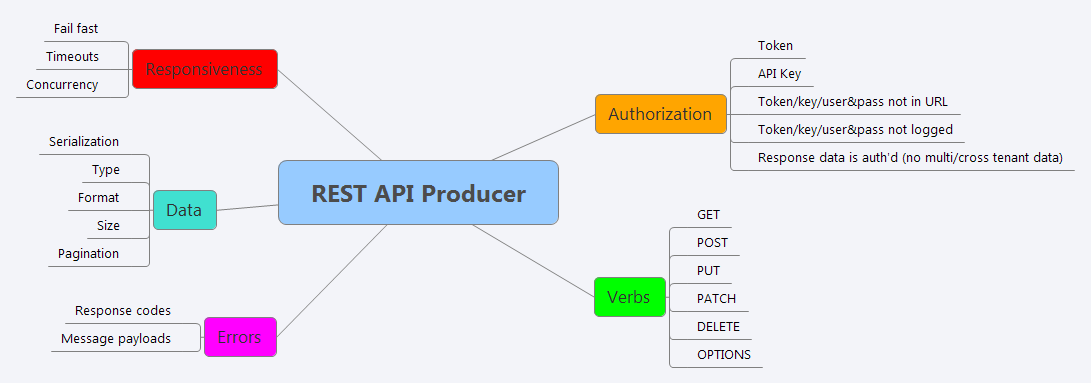
As with the previous heuristic, I have updated the coverage outlines templates originally described and linked in a previous post.
Obviously not all of these branches or leaves will be applicable to your REST API and your context, and indeed the words I use here may mean different things to each of you, but that is sort of the point with a heuristic, it is a guide not a formula, optional not rigid.
Hopefully this will help and possibly inspire some of you to expand your thinking when you need to test a REST API or clarify the requirements around REST API design etc
Feel free to share back your own variations on this heuristic or even your own heuristics.
I have been meaning to share this for a while now.
I have been inspired by, learned from and generally challenged to think more and better by some of the folks that I consider to be thought leaders in testing, namely; James Bach, Michael Bolton and Jonathan Kohl. These are amongst the best thinkers in the testing profession. They are also some of the best at sharing their knowledge, for which I am eternally grateful. I am in some small part trying to mimic them by sharing some of my thoughts and experiences here.
So this is a little overdue homage to these giants upon whose shoulders I am standing.
When trying to come up with ways to help my QA team think more broadly, differently and holistically about risks and tests for Web UI pages I realised that the mind map that I had developed over time for this purpose was not very easy to remember.
This was fine if you used my coverage outline template, (now updated to UNUSUAL PAGE), because that includes both the mindmap and the spreadsheet sections from the mindmap, thus no memory required.
But if you were in a meeting room discussing the user workflow or code design of the latest UI change, or at the desk of the User Experience designer looking over some wire frames in preparation for a 3 amigo style BDD discussion, (designed to ensure we all had a common, shared understanding of the requirements), or a story kickoff where we wanted to think about design and code risks and tests to mitigate those. But you didn’t have a laptop in front of you with the template to hand, how would you mentally run through the different aspects to consider in the context of the work in front of you?
Thinking about how I normally expanded my thoughts around where things could/would go wrong and what sorts of things I should consider testing I realised I often used heuristics I learned from the folks mentioned above. These heuristics were normally memorized in the form of simple mnemonics. Looking again at my mindmap I realised I was not that far from a fairly easy to remember mnemonic, so with a little tweaking I came up with UNUSUAL PAGE (start with URL and go clockwise);
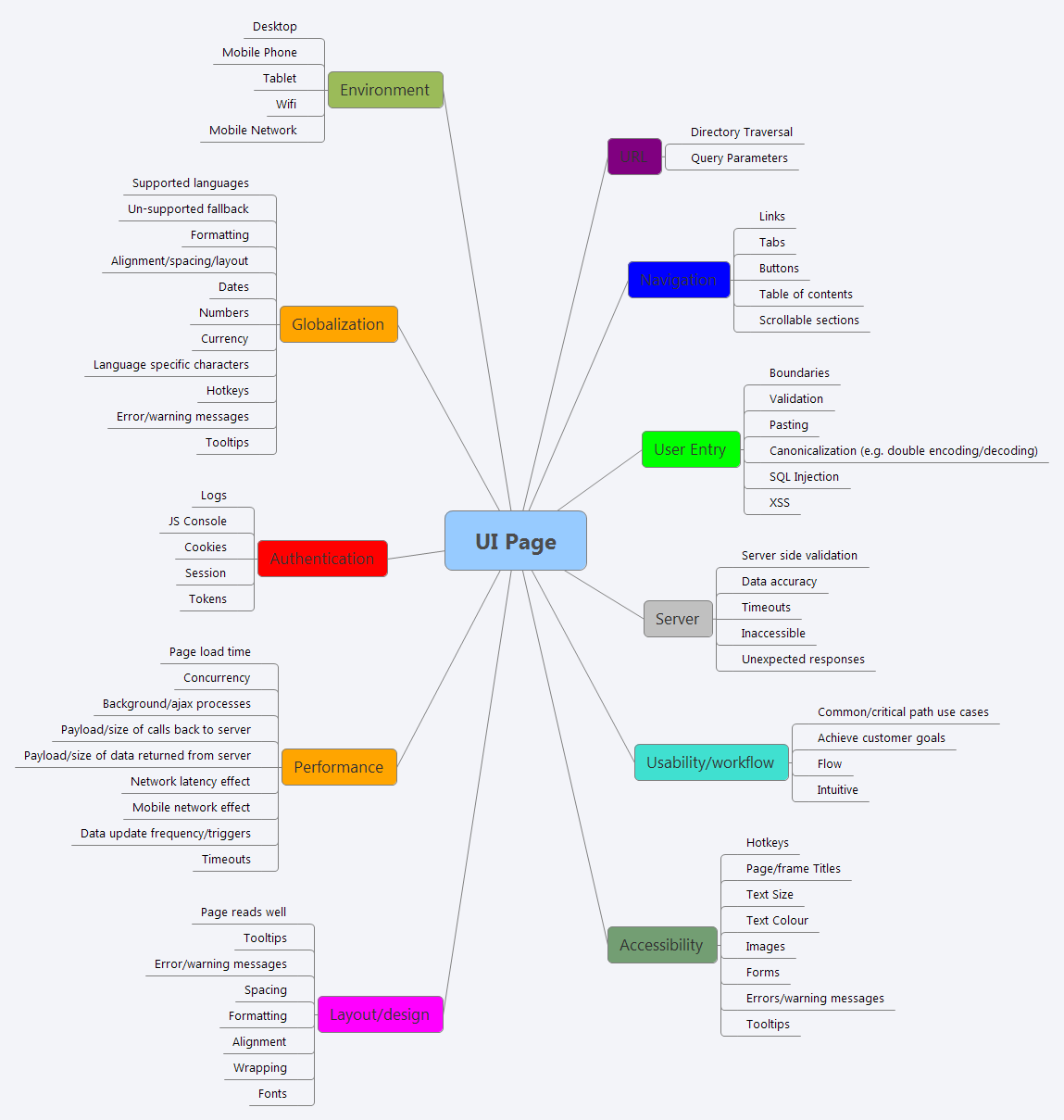
Obviously not all of these branches or leaves will be applicable to your page and your context, and indeed the words I use here may mean different things to each of you, but that is sort of the point with a heuristic, it is a guide not a formula, optional not rigid.
Hopefully this will help and possibly inspire some of you to expand your thinking when you need to test a UI page or clarify the requirements around Web UI design etc
Feel free to share back your own variations on this heuristic or even your own heuristics.
I will share some more that I have been practicing with my team.
There has been a lot of discussion over the last couple of years about test automation and in particular the varying definitions of testing vs checking and how that applies to test automation.
I broadly agree there is a difference, here is my paraphrased understanding of each definition;
Testing – the art and science of conducting experiments and carefully observing the results, all the while making multiple evaluations against explicit and implicit expectations. A fundamentally human, (or manual if you prefer), exercise.
Checking – the deterministic evaluation of the outcome of an action or step such that a pass or fail is recorded.
But there seems to be an underlying theme to most of these discussions, almost a fear. It is as if someone has threatened the existence of manual or human testing.
I do agree that there has been a general drive towards more automation of ‘tests’, and that this has been largely associated with the adoption of agile practices. I myself have encouraged, and in some cases demanded, more investment in, and thus more, automation of tests in companies I have worked for. However, I have also encouraged and hired for manual testing, and have coached and mentored folks to be better exploratory testers (what I call brain engaged testing).
So I don’t subscribe to the fear that manual testing is a thing of the past or an unnecessary overhead. Perhaps this is why I don’t share in the what seems to be an attempt at a sharp delineation between automation and testing?
Like Michael Bolton, I do see automation as a tool and as something that supports testing.
I often use the phrase automation assisted testing, to refer to exploratory or other manual testing where the test setup or initial test data has been achieved using automated tools or scripts.
My preference is to develop automation code in a re-usable fashion, producing a library of re-usable code that is easy to ‘glue’ together in different ways such that different automated tests (or checks if you will) are achievable quickly and efficiently. But this approach also lends itself well to re-using these library ‘functions’ to assist with manual testing. If developed well then anyone with fairly basic coding skills should be able to combine some of these together in order to ‘drive’ a system under test to the point where you want to start your exploration or manual testing. Or as mentioned before, to prime the system under test with the exact data you want or need, in order to conduct the exploratory or manual testing you wish to execute next.
I recently presented my QA Strategy for my current company, Vision Critical, at the VanQ test meetup group. The subtitle for the strategy is Prevention Rather than Cure
Full Youtube video and intro here: http://www.vanq.org/vision-criticals-qa-strategy-prevention-rather-than-cure-stuart-ashman-march-26-2015/
With reference to the original Agile manifesto I present my thoughts on an extension for agile QA or an agile testing manifesto;
While there is value in the items on the right, I value the items on the left more
And to follow that, a set of principles I try to follow and try to instill into those that work with me;
The intention of this post is to get across the idea that your testing strategy should include many layers of testing.
I am talking mostly about automation here and will for the purposes of this post I will ignore the discussion around testing vs checking when it comes to automation, and therefore will continue to use the common terms; tests and test automation.
My first introduction to the formal concept of the ideal test automation pyramid was courtesy of Mike Cohn of Mountain Goat Software (I read his blog post on this many years ago).
The idea he discussed resonated so well with me that I have been trying to follow this strategy ever since. Of course I have experienced a few different companies with very different shapes to their automated testing. I intend to share some of those experiences with you, along with some ideas for how to adjust your strategy in each of those cases, and of course to help you avoid the mistake that Mike was referring to of forgetting about the middle layer.
The test automation pyramid concept has been adopted quite broadly and adapted for many different scenarios too. But it is definitely not a silver bullet and there are times when this approach is not appropriate for your environment, technology or simply the way you work.
That said, most of the companies, technology stacks and teams that I have worked with can and have benefited from this strategy.
So, what is it?
Well here is the most basic version of the pyramid that I typically draw on a whiteboard;
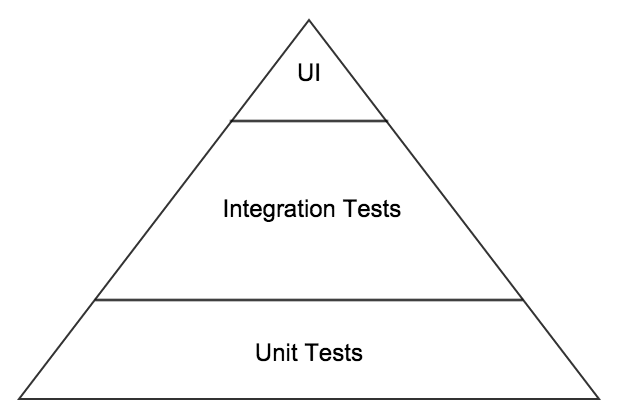
One of the variants that I will often draw, when I feel the need to point out that we still need to do manual testing, (preferably exploratory), is shown below. Because this manual testing is somewhat variable in size or content I add it as a cloud to the top of the pyramid. There are many others who use this style (I don’t claim to have been the first but I cannot remember where I initially saw this in order to provide appropriate credit).
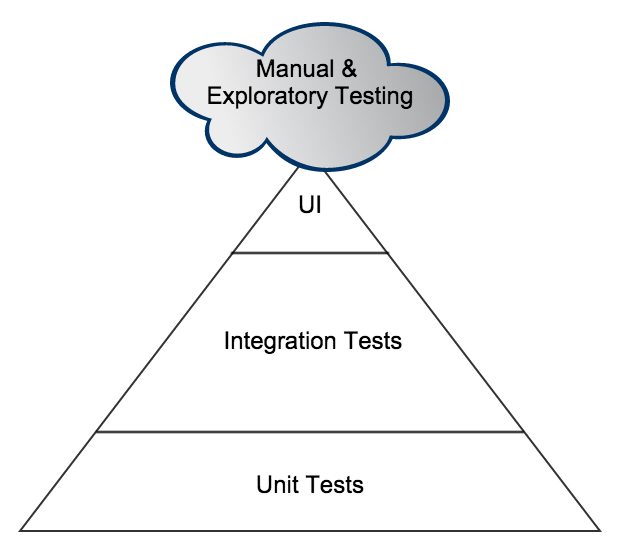
But the variant I use most often is one where I split the integration section in two, and talk about code component integration and system component integration;
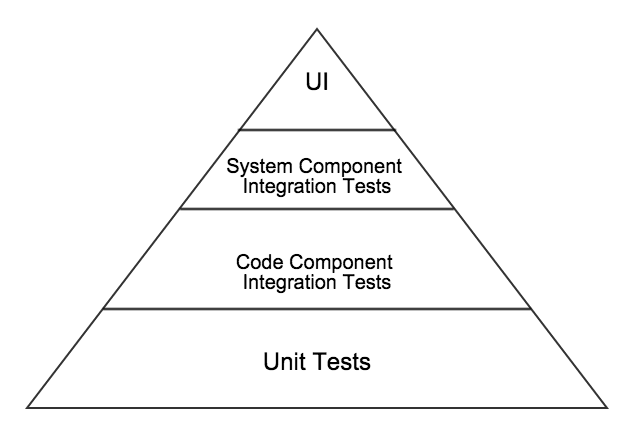
Having done that I feel that I really need to explain my layers more clearly;
Unit tests – tests that are designed to ensure the smallest divisible pieces of code (units or components) are working the way they were intended. These are typically written by developers (though I encourage QA folks with development skills to at least review if not write some of them). They are typically written to make use of a unit test framework. They are often written after the code that they are intended to test is written, though in most cases I would prefer them to be written first (in a TDD manner). They should be executable by a developer at any time and are typically the first tests run in a CI system (Continuous Integration System).
A web based application may have unit tests in more than one code base, for example you may have Javascript Unit Tests in addition to those in the back end or server side code or even API code.
Integration tests at the code component level – tests that are designed to ensure that the code units or code components that need to work with each other (one calls another, passes data onto another etc), do so in the expected way(s). These are typically written by developers (though again I encourage QA folks with development skills to review and perhaps add tests here too). These will also often make use of a unit test framework but will be typically run after the unit tests have run (and passed).
Integration tests at the system component level – tests that are designed to ensure that the system components that need to interact with each other can do so as intended. These may be written either by developers or QA folks with programming skills. These tests will be designed and executed against APIs or Windows services or any interfaces exposed between system components. Sometimes you may have 3rd party services or components involved in this layer, for example we are currently using some cloud based services in our application. Often the UI will be built on top of an API, and by focusing on testing at this layer you can more efficiently and more robustly test the variations and permutations of API calls. Thus providing a solid, (well tested or checked), API layer upon which to provide a much smaller set of UI tests, as these will just need to prove that the UI interacts as expected with all the code layers below, and that in turn they all interact together well, (you will have covered the broad variations in this in the layer below too). These tests will need to be run against a deployed build in the CI pipeline, as these will typically need the application to be installed/deployed in an environment similar to way it will be delivered in production. As such these are normally run after the code component integration tests have run and passed.
UI tests – tests that are designed to ensure the user interface works in the way that was intended. Keep in mind that the user interface is not necessarily a web page or a GUI, it could just as easily be a command line interface to a tool. Typically though we are talking about a web based UI or a GUI of some kind. Test automation at this layer is often expensive both to produce and to maintain over time. So the focus here should be to minimise these automated tests by relying on and building on the successes of the testing in the layers below. Focus here on simple end to end workflow through the UI, and ensure your tests focus only on the sections of the UI that you want to prove are working well. In other words utilise lower levels of testing to prime the system under test with appropriate test data etc. For example: using the API test code to enter test data or get the system into a certain state that you need to start testing a UI workflow from. These are normally the last tests run in the CI system and sometimes are not run in a continuous way at all. For example if your UI tests take 4 hours to run then you won’t usually be able to run them on every check in and will instead need to consider running them periodically say once or twice a day.
(We can talk about opportunities to reduce this time later but the best one is to simply reduce the number of tests you need to run at this level by ensuring you have most of the coverage you need in lower levels).
So, why are the layers ordered and sized the way they are?
Well, I typically think of the width of each layer being the number of tests. This provides a relatively easy way to measure to see if you are approximating the right shape. As with most metrics I would caution you using this too strictly as really you just want to see that you are trending the right way or are in a position to discuss why not, (and perhaps understand that you have valid reasons).
The reason they are layered in this order is really the building analogy, where the bottom layer of unit tests is really forming the foundational layer of tests for the rest to be built on. You want a very broad bottom layer (a large numbers of unit tests as the scope of each test is very small but the permutations and variations you need to cover may be broad).
As you move up the pyramid you will need less tests as the type of test increases in scope (covers more with one test) and because you don’t need to cover all permutations or variations as most should have been covered in the layer below.
You will have noticed in the definitions that I mention CI systems and when the tests will typically run. This is following the same pattern, you will only run the tests of a higher layer once the tests that are providing a foundation for that layer have run and passed. If there are failures you typically want to stop and resolve those issues before moving on.
It is also worth mentioning that the lower the layer the ‘cheaper’ the testing is, e.g. unit tests are typically quick to write, and very fast to run. So having lots of permutations or variations of say data or parameters tested at this layer is relatively cheap and easy, (much cheaper than at the UI layer). Thus this layer can provide a very solid foundation for the higher layers where you may only need to test one or two permutations or variations of data or parameters as you will know that the rest have already been covered and that the higher level test is more focused on proving interaction between parts of the system or the system as a whole.
One of my previous colleagues (Caroline), always preferred to think of the layers of testing as layers of a multi-tiered cake, like a wedding cake.
I prefer the pyramid shape myself so I continue to use that as my illustration.
Here are some of the shapes I have experienced and some approaches we have used to improve the situation:
That said One company I worked at did not really have a pyramid at all, it was more like a unit test cake with a manual smoke test cherry on top
This was a very developer heavy company where developers were expected to deliver production ready code, so they were expected to test their own code. Which typically meant they wrote unit tests and not much more.
If the code compiled and could be installed then it was largely assumed to be good.
The unit testing was not, in my humble opinion, great or consistently applied. The usual patterns and problems of some developers doing a better job than others and no or very little measurement of coverage.
The tests were also typically written after the code (so not TDD), meaning that the tests typically just confirm that the code does what the developer wrote the code to do, and are not trying to ensure that the solution in code is a robust one that will handle interesting or unusual cases appropriately.
If you find yourself in this situation and you have quality problems, (if this is working for you then no need to fix it), then I would suggest you try to find examples of product failures that are as a result of failures in system component level integration or code component level integration. For example an API that was accepting invalid input from the UI and failing as a result. Use these to encourage the developers to add integration tests, by helping them to understand the missing tests (the ones that could have exposed these issues early).
You will also need to seek management support to ensure new code written has code and system component level tests delivered with it as well as the unit tests. It should be fairly easy to monitor and show that this is happening and provide feedback on some of the issues these extra tests are exposing.
Once you start seeing automated tests running and passing at the code and system component levels you can then start to add UI level tests (probably best to start by automating those smoke tests).
A common scenario, (in my experience, and the experiences that others have shared with me), is an upside down or inverted pyramid, where the testers have focused on adding automation at the UI layer, with very little being done at the lower layers. There may have been some automation focused on service or API layers. The developers have not been encouraged or managed to producing much in the way of unit tests so this is the smallest of all the layers.
Sometimes this happens when an organisation purchases an expensive test automation tool and wants to see a return on that investment, so focuses or manages the team to that, resulting in lots of UI centric automated tests.
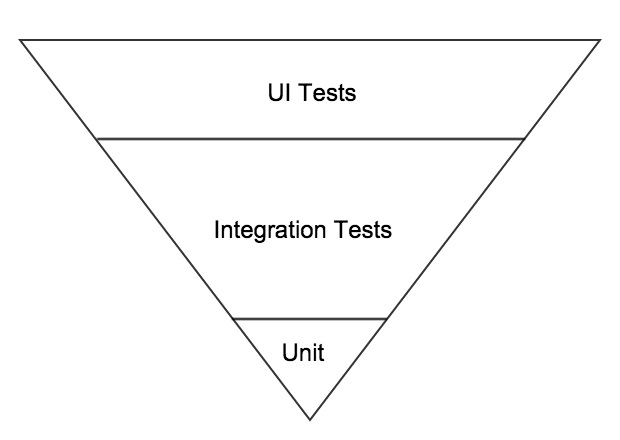
The way to ‘flip’ the pyramid in this situation is to set the expectation that all new code needs to have unit tests delivered along with it, and any existing/legacy code that is changed should also have unit tests added (where this is possible and cheap enough to do – code that was not written with unit tests in mind can sometimes be very hard to add unit tests for. If new code is written using a TDD approach or at least with the intention that unit tests need to be delivered too then it will be more ‘unit testable’ by design). Again you will need management support or buy in for this, as some may question the value of the extra time or investment required in providing these tests. Try to find some existing issues that could have been easily and cheaply exposed at this layer, or pay attention to those that are exposed by your new tests and celebrate them. Assuming, that you see unit tests being added and passing, then you can start to encourage code and system component level tests by looking at important interactions in both those layers and focusing on those first (critical components at both code and system levels). You should also look at your UI tests and see if these can start to be refactored to either use more API or service level integration or perhaps even be replaced by tests at that layer.
An interesting variation is one that I call trapezoidal, since it feels like there are two trapezoidal sections of tests with a thin and narrow band of integration tests in between, in extreme cases perhaps none at all. So this is really depicting a reasonable amount of unit tests along with a focus on UI tests and very few integration tests of any sort. This, I feel, is the very problem that Mike was focused on with his original blog post, and it is a shame that this is still a pattern we can see today.
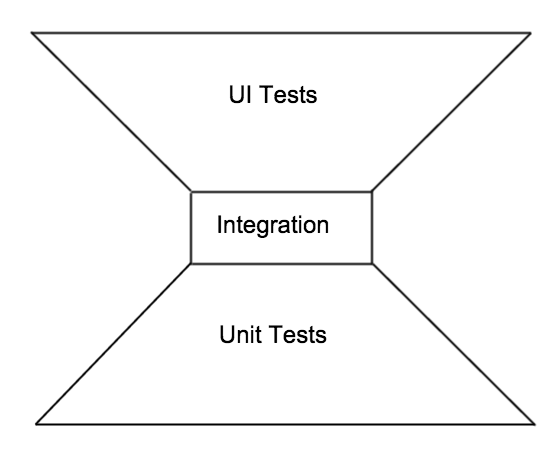
For this company it seemed the automated testing was divided between dev and QA in terms of, “is it a unit test?” then dev will provide that, anything else must be a QA test and that typically means testing as the customer so a UI test.
There are many reasons why we seem to ignore the integration tests, here are a couple of the most common ones I have witnessed;
So in order to combat this shape, the team(s) really need to focus on adding integration tests, both at the code component and the system component levels. This will again require investment and support, so as before try to identify the critical code components and system components and focus your efforts on these first, or simply start applying this with all new code and only tackle existing code if it is changing significantly. Once you see these system and code components being covered more efficiently and effectively using integration tests you can probably reduce the number of UI test variations that interact with these system and code components. It may be possible to divide the efforts here neatly between QA folks with programming experience who can tackle and get the benefit of a greater understanding of the system component integration points, and the developers who can more readily identify and develop tests for the critical code components.
Make sure your tests are identifiable in some way so that progress can be shown and measured and that issues found can be attributed to the appropriate layer in which they were found so that these successes can be shared and celebrated, providing validation of the efforts it took to add these.
Fork and ambush is my short way of describing the outcome of non-collaborative work on a story or the implementation of a requirement. I used to see this all the time in more waterfall like environments, but I am sad to say I still see and hear of this in more agile environments too.
The scenario is as follows;
Someone, usually the customer proxy, in my current company this is a Product Manager, provides a requirement, in our case a story along the lines of “As a …. I would like … so that I can …”
The Developer would then take this story and go back to his or her desk and start developing the code to deliver the functionality for the story.
The QA or tester would take this story and go back to his or her desk and start thinking about test cases that should be executed against the story.
This is the fork (both going their separate ways to think about the story individually)
Some time later …
When the story is developed the developer notifies the tester and testing begins.
This is effectively the ‘ambush’ part.
The tester is often trying to find fault with the developer by hunting for bugs in the developed code.
Often a bug turns out to be a difference of interpretation (of the story) between the developer and the tester
In the worst case the customer proxy (e.g. Product Manager), comes along to diffuse the argument and informs them both that they are both wrong and what has been delivered is not what was required and the tests are also incorrect.
So, how can this be better?
Using a more BDD like approach, where the three amigos (Developer, Tester and Product Manager) discuss the requirement first.
Making sure each of them understands what is required (scope of work), who it is for (who the customer is), and why it is important to them.
They confirm this understanding by defining collaboratively the set of tests that will be used to prove what has been delivered is acceptable to the customer (what they needed and working in the way they need it to).
Then if the developer and tester fork at all then they both have a clear understanding of what is required.
The developer can ensure the developed code passes the acceptance tests.
The tester can ensure that in addition to passing the acceptance tests the developed code does not do anything unexpected and conforms to any non functional requirements that may have also been discussed etc.
The conclusion then is more likely to be a successful delivery as the work would not be accepted if the acceptance tests do not pass, and the developer and tester are on the same page as the Product Manager and can all see how they can work together towards the common goal.
 I was looking back over some notes from previous positions and I came across an instance where I had experienced what I called a Canary Fail. I am sharing this in the hope that some of you can learn from this rather than having to experience this for yourselves first hand.
I was looking back over some notes from previous positions and I came across an instance where I had experienced what I called a Canary Fail. I am sharing this in the hope that some of you can learn from this rather than having to experience this for yourselves first hand.
This was quite simply a couple of situations where the customer found issues I knew were there but had not yet raised them with my team. I have always maintained that one of the primary purposes of a tester, in the context of discovering and providing information about the quality of the product, is to be the canary in the coal mine. In other words to be the early warning system, to raise the alarm to avert disaster.
Why is it then that I failed in this regard? Well, there are no excuses, I was wrong and I really should have known better. This was a lesson well learnt! Of course there are plenty of contributing factors that conspired to help me make poor decisions, and I am sure these will be familiar to at least some of you;
The root cause of my canary fail was that I held off on reporting these issues because I was concerned I was wrong, that my understanding and thus my testing was flawed in some way and this would lead to me crying wolf! This in turn would result in me losing credibility as a tester and thus weaken my ability to advocate for defect fixes.
So the lesson I learned painfully was to raise a flag early and to talk through my concerns openly. Then to trust in the professionalism of my colleagues to forgive me when I am mistaken but to treat each flag I raise with respect and not discount my concerns even if I cried wolf last time.